DTW最初用于识别语音的相似性。我们用数字表示音调高低,例如某个单词发音的音调为1-3-2-4。现在有两个人说这个单词,一个人在前半部分拖长,其发音为1-1-3-3-2-4;另一个人在后半部分拖长,其发音为1-3-2-2-4-4。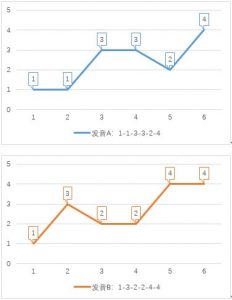 继续阅读“语音识别初探(二)DTW算法简介”
继续阅读“语音识别初探(二)DTW算法简介”
标签: 机器学习
语音识别初探(一)
象棋盲棋训练软件的开发要用到棋步的语音识别,试了下国内一些成品,在没增加个性语音库和仔细调参的情况下,识别结果大概是这样子的:
“相三进五”识别为“象山劲舞”,
“相七进九”识别为“象棋敬酒”,
“仕四进五”成了“四四静五”等等。
以上结果没法进行实质性的使用。因此花点时间学习一下语音识别方面的知识就在所难免了,这个系列记录一下学习过程并备忘。
继续阅读“语音识别初探(一)”
简易象棋连线器升级版(卷积神经网络应用实例)
前面那个象棋连线器简易版,总有那么几个盘面图识别不完整。本次基于深度学习框架tensorflow搭建卷积神经网络,利用自己的棋盘图文件制作类cifar10棋子数据集,再通过训练好的cnn模型,识别出完整棋盘图的fen串。制作方法如下:
1、用自己的棋盘图文件制作类cifar10棋子数据集。采集样本图像,把不同兵种的棋子图像文件分别存于工作目录 _strWorkingFolder 下不同的子文件夹中,子文件夹依次命名为类别名(如rook、knight共10类),图像文件名则随意。
2、用renBatchImag()函数按照“类别名_顺序号.jpg”的形式批量重命名各类别子文件夹下所有图像文件,如:”rook_1.jpg”、”rook_2.jpg”和”knight_1.jpg”、”knight_2.jpg”。这步也可省略。
3、用img2bin()函数把全部准备好的样本图像生成想要的二进制数据集(含data_batch_x.bin、test_batch.bin及makeBatchesMeta.txt等7个文件)。 CCifar10 binData; binData.img2bin( “c:\\dl\\Pieces”);
4、将 tensorflow/models/image/cifar10 模块中获取数据的部分参数修改成为适合自己数据集。
5、完成在自定义数据集上用 tensorflow/models/image/cifar10 模块的源码训练测试。
6、输入棋盘图,输出fen串,搞定。
Python开发环境Spyder极简介绍
spyder的官方文档:
https://pythonhosted.org/spyder/
Tensorflow入门(浅显易懂的例子更容易豁然开朗)
节选自“https://blog.csdn.net/vagrantabc2017/article/details/77002231”
Tensorflow API分两类:
TensorFlow Core:适合细粒度的控制模型。
高层API:如 tf.contrib.learn,是对core的封装,更好用。但contrib目前不稳定。TensorFlow程序分两块:1)构造计算图 2)运行计算图
计算图由节点和边组成,程序不会刻意构造边。
节点包括:常量节点,操作节点,占位符节点,变量节点等。
继续阅读“Tensorflow入门(浅显易懂的例子更容易豁然开朗)”
局面评估初探
1、基本概念
棋局达到特定盘面,到底孰优孰劣,就需要一个数学模型来进行静态判定,这个进行静态判定的数学模型通常也叫评估函数。记忆中高等数学里有关多项式的内容中表示,不管多么复杂的评估函数,都可以用多项式逼近这个函数(泰勒公式?)。这个多项式是影响局面优劣的各种因素量化后的加权和。从而问题最终归结于如何选择影响局面优劣的因素及对应的权重,最后计算出多项式的值即为局面评价最终得分。 继续阅读“局面评估初探”